It shows how to use MCP in an autonomous AI agent
MCP Manus
여기에서는 MCP (Model Context Protocol)을 이용하여 Manus와 같은 완전 자동화 에이전트(Autonomous AI Agent)을 구현합니다. Manus는 planning을 통해 스스로 자기가 해야 할 checklist을 작성하고 multi agent를 이용해 효율적으로 주어진 task를 수행합니다. 이러한 agent 동작은 Bedrock-Manus: AI Automation Framework Based on Amazon Bedrock와 LangManus을 참조하였습니다.
MCP를 이용하면 다양한 데이터 소스를 쉽게 연결하여 AI 애플리케이션을 개발할 수 있습니다. 여기에서는 LangChain MCP adapter을 이용해 다수의 MCP server로 부터 tool에 대한 capability를 가져오고 이를 이용해 적절한 task를 수행합니다. 또한 LangGraph Builder를 이용해 MCP Manus Agent를 쉽게 설계함으로서 추가적인 수정 및 이해의 편의성을 높입니다. 전체적인 Architecture는 아래와 같습니다. MCP Manum는 개인 PC등에서 local에 설치하여 사용할 수 있으며, 필요시 아래와 같이 EC2에 container형태로 deploy하여 활용할 수 있습니다. 이때 Lambda를 이용해 RAG를 활용하고 MCP server를 이용해 tavily, wikipedia와 같은 외부 데이터를 활용할 수 있습니다.
주요 구현
LangGraph Builder를 이용해 Manus Workflow 구현
LangGraph Builder를 이용해 Manus Workflow를 정의합니다. Langgraph Builder에 접속하여 아래와 같이 workflow를 그린 후, 오른쪽의 code generator 버튼을 이용해 LangGraph 코드를 생성합니다. 이후 생성한 stub.py, spec.yml, implementation.py을 visual studio나 cursor로 다운로드 한 후 필요한 노드를 구현합니다. 상세 내용은 LangGraph Builder로 Agent 개발하기을 참조합니다.
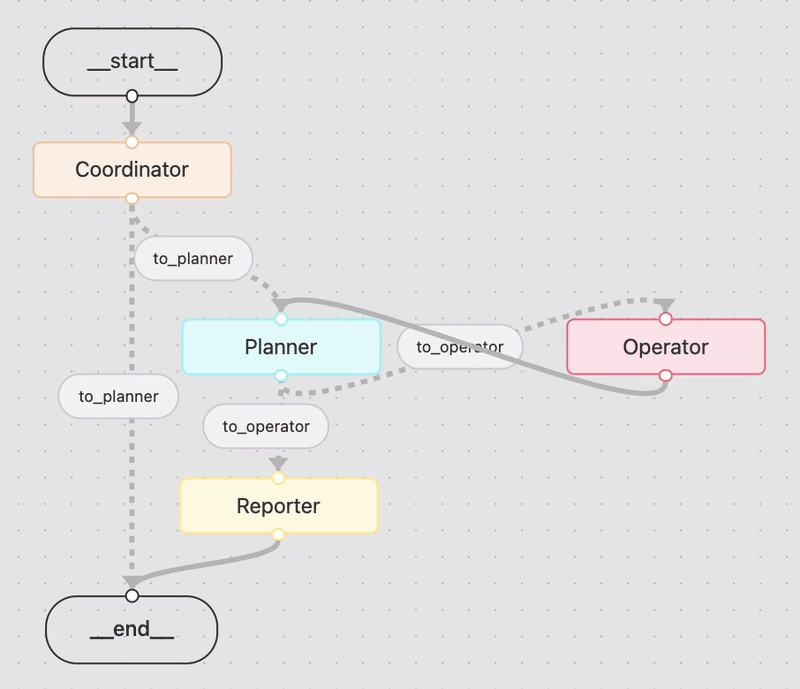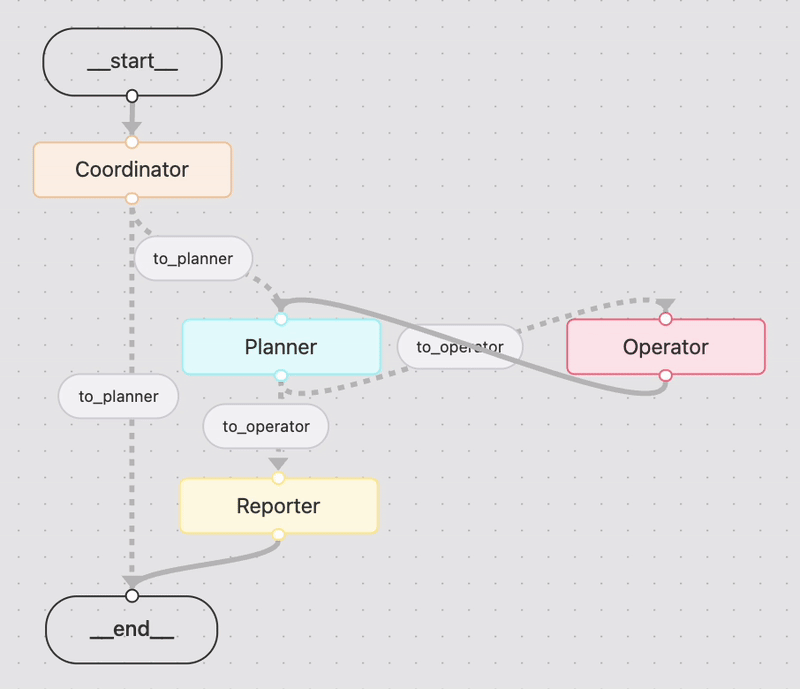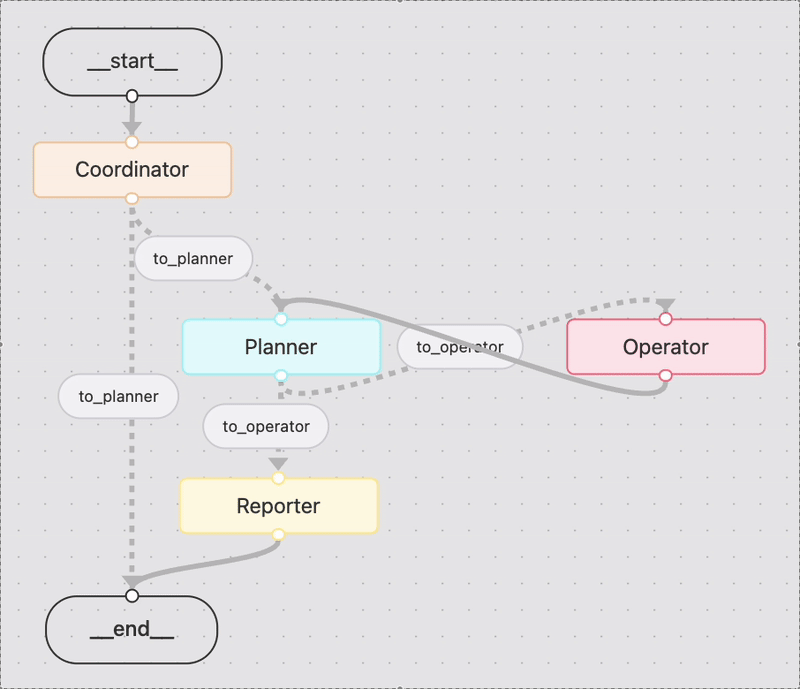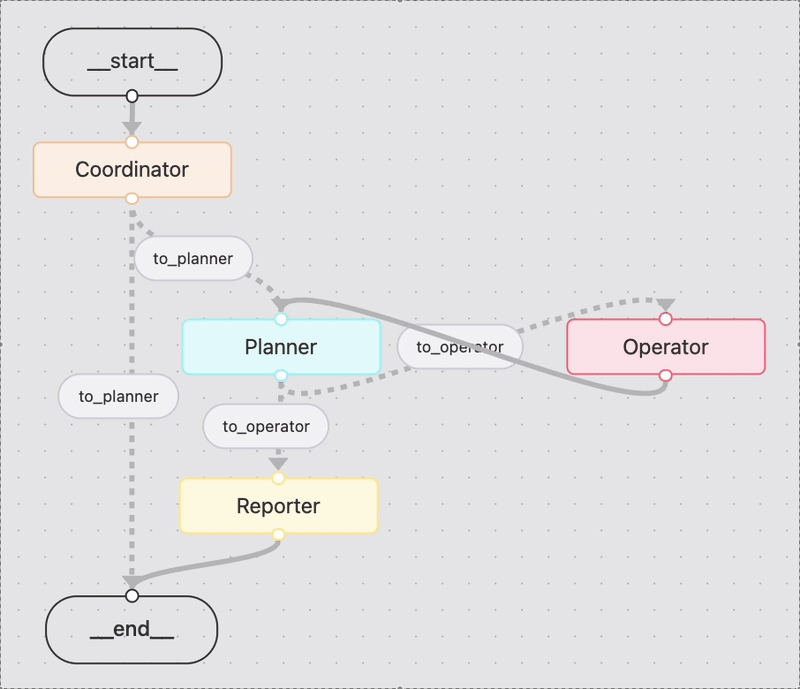
이를 LangGraph Studio를 이용해 graph 형태로 그리면 아래와 같습니다.
State 구현
Manus와 같은 완전 자동화된 agent를 구현하기 위하여 Planning을 활용합니다. 이를 위해 state에는 현재 계획에 대한 full_plan을 정의하고, LLM이 순차적으로 수행할 계획을 설정합니다. 또한 연속되는 동작의 결과를 저장하기 위하여 messages를 활용합니다. 최종 결과와 생성된 report는 final_response와 report를 활용해 저장되고 채팅창에 표시됩니다.
class State(TypedDict):
full_plan: str
messages: Annotated[list, add_messages]
final_response: str
report: str
Multi-agent 구현
여기서 LangGraph로 구현된 Agent 구조는 아래와 같습니다. 상세한 코드는 stub.py을 참조합니다. Coordinate는 사용자의 요청이 planning이 필요한 지 판단하여, planning이 필요한 경우에만 라우팅을 수행합니다. planning은 prompt를 planner.md을 이용해 system prompt를 생성하고, 적절한 plan을 생성합니다. 이후 Operator는 plan에서 지정한 tool을 수행하게 됩니다. tool 실행시 하나의 agent를 생성하므로 전체적인 구조는 multi agent 형태로 동작합니다.
# Add nodes
builder.add_node("Coordinator", nodes_by_name["Coordinator"])
builder.add_node("Planner", nodes_by_name["Planner"])
builder.add_node("Operator", nodes_by_name["Operator"])
builder.add_node("Reporter", nodes_by_name["Reporter"])
# Add edges
builder.add_edge(START, "Coordinator")
builder.add_conditional_edges(
"Coordinator",
nodes_by_name["to_planner"],
[
END,
"Planner",
],
)
builder.add_conditional_edges(
"Planner",
nodes_by_name["to_operator"],
[
"Operator",
"Reporter",
],
)
builder.add_edge("Operator", "Planner")
builder.add_edge("Reporter", END)
Coodinater의 구현
Coordinatr는 coordinator.md을 이용하여 system prompt를 생성한 후에 사용자의 입력을 처리합니다. 이때 prompt에 의해서 to_planner로 라우팅이 필욯다마녀 final_response을 to_planner로 설정하여 전달합니다.
def Coordinator(state: State) -> dict:
question = state["messages"][0].content
prompt_name = "coordinator"
system_prompt=get_prompt_template(prompt_name)
llm = chat.get_chat(extended_thinking="Disable")
coordinator_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{question}"),
]
)
prompt = coordinator_prompt | llm
result = prompt.invoke({
"question": question
})
final_response = ""
if result.content.find('to_planner') == -1:
result.content = result.content.split('<next>')[0]
final_response = result.content
return {
"final_response": final_response
}
Planner의 구현
Planner는 planner.md을 이용해 system prompt를 구성합니다. 이때 planner의 input으로 state 전체를 전달하는데, full_plan과 messages를 이용해 plan을 업데이트 할 수 있습니다. planner.md의 prompt에 의해서 LLM이 plan을 완료하였다고 판단이 되면 tag에 "Completed"라고 전달합니다. 이를 확인하여 messages의 마지막 항목을 final_response를 설정할 수 있습니다. state가 "Proceeding"이라면 생성된 plan을 리턴합니다.
def Planner(state: State) -> dict:
prompt_name = "planner"
system = get_prompt_template(prompt_name)
human = "{input}"
llm = chat.get_chat(extended_thinking="Disable")
planner_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", human),
]
)
prompt = planner_prompt | llm
result = prompt.invoke({
"team_members": team_members,
"input": state
})
output = result.content
if output.find("<status>") != -1:
status = output.split("<status>")[1].split("</status>")[0]
if status == "Completed":
final_response = state["messages"][-1].content
return {
"full_plan": result.content,
"final_response": final_response
}
return {
"full_plan": result.content,
}
Operator의 구현
생성된 plan에 따라서 Operator는 적절한 tool을 실행합니다. 이때 tool은 MCP로 부터 얻은 tool 정보를 활용하여 독립된 agent로 동작합니다. 여기에서는 operator.md의 system prompt를 이용하여, 수행할 tool과 동작을 next와 task로 얻습니다. 사용 가능한 tool의 정보는 MultiServerMCPClient로 부터 얻어옵니다.
async def Operator(state: State) -> dict:
prompt_name = "operator"
system = get_prompt_template(prompt_name)
human = "{input}"
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", human),
]
)
llm = chat.get_chat(extended_thinking="Disable")
chain = prompt | llm
result = chain.invoke({
"input": state,
"team_members": team_members
})
result_dict = json.loads(result.content)
next = result_dict["next"]
task = result_dict["task"]
if next == "FINISHED":
return
else:
tool_info = []
for tool in tool_list:
if tool.name == next:
tool_info.append(tool)
agent, config = chat.create_agent(tool_info)
messages = [HumanMessage(content=json.dumps(task))]
response = await agent.ainvoke({"messages": messages}, config)
output = response["messages"][-1].content
return {
"messages": [
HumanMessage(content=json.dumps(task)),
AIMessage(content=output)
]
}
Reporter의 구현
reporter.md을 활용하여 보고서를 생성합니다. 최종 보거서는 이전 steps에서 수행된 결과를 모아서 아래와 같이 prompt로 결과를 요약합니다. 이전 수행된 결과들은 request_id를 이용해 조회할 수 있고, 이때 얻어진 결과를 다시 markdown 형태의 파일로 저장합니다. 이 markdown 파일을 S3에 저장되며, CloudFront를 이용해 조회될 수 있습니다.
def Reporter(state: State, config: dict) -> dict:
prompt_name = "Reporter"
request_id = config.get("configurable", {}).get("request_id", "")
key = f"artifacts/{request_id}_steps.md"
context = chat.get_object(key)
system_prompt=get_prompt_template(prompt_name)
llm = chat.get_chat(extended_thinking="Disable")
human = (
"다음의 context를 바탕으로 사용자의 질문에 대한 답변을 작성합니다.\n"
"<question>{question}</question>\n"
"<context>{context}</context>"
)
reporter_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", human)
]
)
question = state["messages"][0].content
logger.info(f"question: {question}")
prompt = reporter_prompt | llm
result = prompt.invoke({
"context": context,
"question": question
})
logger.info(f"result of Reporter: {result}")
key = f"artifacts/{request_id}_report.md"
chat.create_object(key, result.content)
return {
"report": result.content
}
MCP의 활용
여기에서는 MCP-github에서 생성한 MCP server들을 활용합니다. 아래와 같이 메뉴에서 필요한 MCP 서버를 선택한 후에 질문을 입력하면 아래와 같이 tool들에 대한 정보를 MCP server로부터 가져옵니다. 아래와 같이 필요한 MCP server를 선택합니다.
활용 예제
"aws document", "aws diagram", "tavily"을 선택한 후에 "aws에서 생성형 AI chatbot을 RAG와 함께 구현하는 방법?"을 입력하면 적절한 plan을 생성합니다. 이때, 사용할 수 있는 tool은 read_documentation, search_documentation, recommend, generate_diagram, get_diagram_examples, list_icons, tavily-search, tavily-extract 입니다. 이를 이용해 생성한 plan의 예는 아래와 같습니다.
## Title: AWS 생성형 AI Chatbot with RAG 구현 가이드
## Steps:
### 1. search_documentation: AWS RAG 및 Chatbot 관련 문서 검색
- [x] Amazon Bedrock 관련 문서 검색
- [x] RAG 구현 관련 AWS 문서 검색
- [x] Amazon Kendra와 OpenSearch 관련 문서 검색
- [x] AWS Lambda와 API Gateway 관련 문서 검색
### 2. read_documentation: 핵심 문서 상세 분석
- [ ] Bedrock 구현 가이드 분석
- https://docs.aws.amazon.com/prescriptive-guidance/latest/retrieval-augmented-generation-options/rag-custom-retrievers.html
- https://docs.aws.amazon.com/bedrock/latest/userguide/evaluation-kb.html
- https://docs.aws.amazon.com/nova/latest/userguide/rag-systems.html
- [ ] RAG 아키텍처 구현 방법 분석
- [ ] Kendra/OpenSearch 통합 방법 분석
- [ ] Lambda 함수 구현 가이드 분석
- https://docs.aws.amazon.com/lambda/latest/dg/services-apigateway.html
- https://docs.aws.amazon.com/lambda/latest/dg/services-apigateway-tutorial.html
### 3. generate_diagram: RAG 기반 Chatbot 아키텍처 다이어그램 생성
- [ ] 전체 시스템 아키텍처 다이어그램 생성
- [ ] 데이터 흐름 표시
- [ ] 주요 AWS 서비스 연동 구조 표시
- [ ] 사용자 요청부터 응답까지의 프로세스 플로우 표시
### 4. tavily-search: 추가 구현 사례 및 모범 사례 조사
- [ ] AWS RAG 구현 사례 검색
- [ ] 성능 최적화 방법 조사
- [ ] 비용 최적화 방안 조사
- [ ] 보안 구성 모범 사례 조사
이때 생성된 결과는 아래와 같습니다.
실행하기
Output의 environmentformcprag의 내용을 복사하여 application/config.json을 생성합니다. "aws configure"로 credential이 설정되어 있어야합니다. 만약 visual studio code 사용자라면 config.json 파일은 아래 명령어를 사용합니다.
code application/config.json
venv로 환경을 구성하면 편리합니다. 아래와 같이 환경을 설정합니다.
python -m venv venv
source venv/bin/activate
이후 다운로드 받은 github 폴더로 이동한 후에 아래와 같이 필요한 패키지를 추가로 설치 합니다.
pip install -r requirements.txt
deployment.md에 따라 AWS CDK로 Lambda, Knowledge base, Opensearch Serverless와 보안에 필요한 IAM Role을 설치합니다. 이후 아래와 같은 명령어로 streamlit을 실행합니다.
streamlit run application/app.py
EC2에 배포하기
EC2가 private subnet에 있으므로 Session Manger로 접속합니다. 이때 설치는 ec2-user로 진행되었으므로 아래와 같이 code를 업데이트합니다.
sudo runuser -l ec2-user -c 'cd /home/ec2-user/mcp-manus && git pull'
이제 아래와 같이 docker를 빌드합니다.
sudo runuser -l ec2-user -c "cd mcp-manus && docker build -t streamlit-app ."
빌드가 완료되면 "sudo docker ps"로 docker id를 확인후에 "sudo docker kill" 명령어로 종료합니다.
이후 아래와 같이 다시 실행합니다.
sudo runuser -l ec2-user -c 'docker run -d -p 8501:8501 streamlit-app'
만약 console에서 debugging할 경우에는 -d 옵션없이 아래와 같이 실행합니다.
sudo runuser -l ec2-user -c 'docker run -p 8501:8501 streamlit-app'
실행 결과
Streamlit에서 보여주는 chatbot UI는 전체 결과를 보여주기 어려우므로 아래와 같이 web page를 이용해 결과를 확인하고 공유합니다. 아래는 "DNA의 strands에 대해 설명해주세요."라는 질문에 대한 결과입니다. 계획은 아래와 같이 checklist 형태로 주어지며, tavily-search, search_papers, repl_drawer, repl_coder가 목적에 맞게 활용됩니다.
단계별 실행 결과에는 각 tool들의 결과가 아래와 같이 순차적으로 저장됩니다.
이후, 최종적으로는 아래와 같은 결과 리포트가 생성됩니다. 리포트가 길어서 표시되지 않았지만, 최종 결과는 단계별 실행 결과를 모아서 장문의 리포트를 생성하게 됩니다.