MCP server by VulcanLab
MCPThreatHive: An Automated Threat Intelligence and Live Risk Validation Platform for Model Context Protocol Agent Ecosystems
Manual threat modeling for complex agentic systems is overwhelming. MCPThreatHive automates the discovery, analysis, and visualization of security risks in your MCP ecosystem.
📹 Platform Demo:
The Problem
- Rapidly Evolving Threats: New MCP vulnerabilities and LLM attack vectors emerge daily.
- Static Analysis isn't Enough: Merely checking configuration files misses runtime and ecosystem threats.
- Data Overload: Security teams can't manually process thousands of RSS feeds, CVEs, and GitHub issues.
- Visibility Gap: It's hard to visualize the attack surface of a complex agentic swarm.
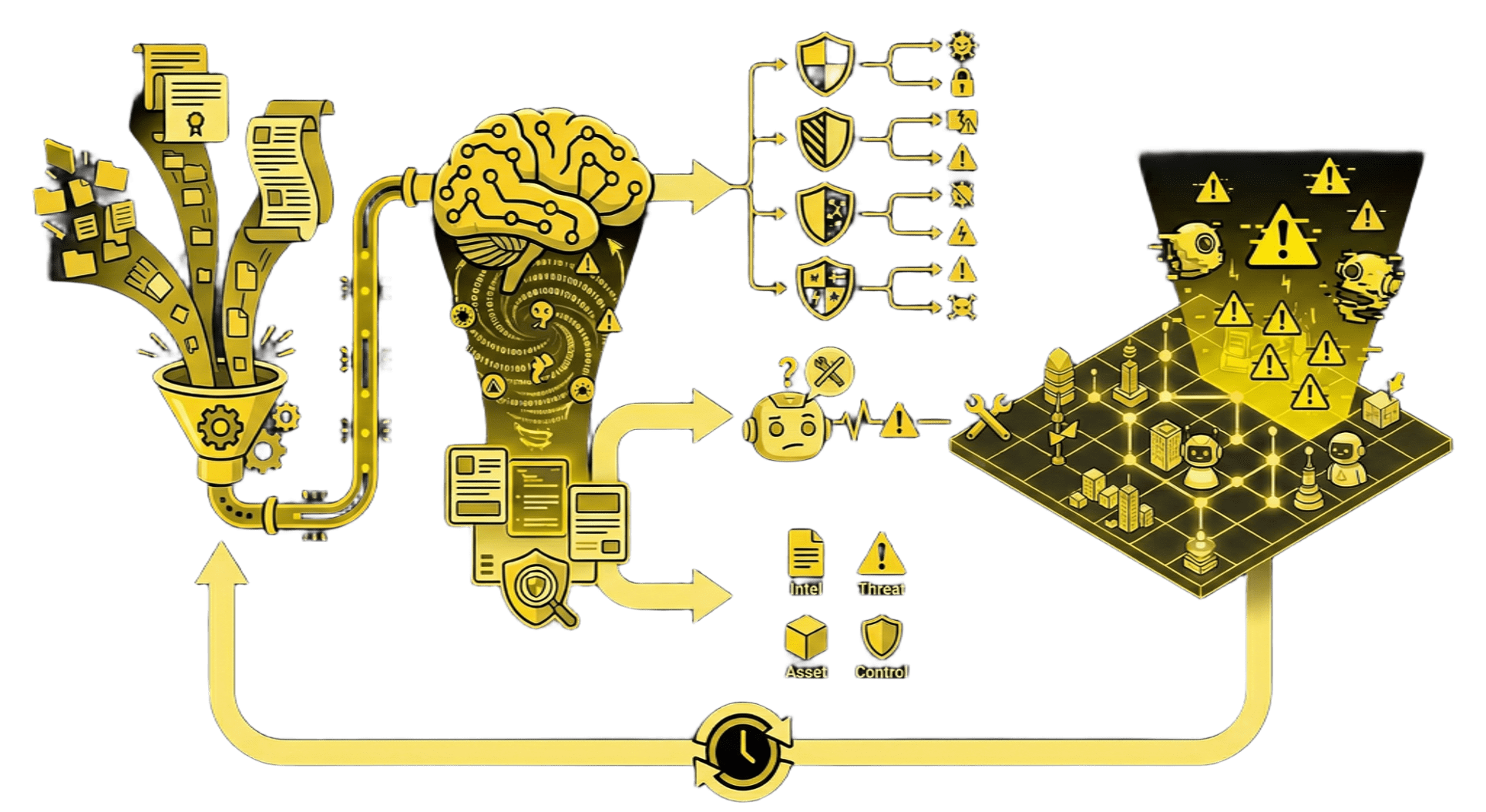
We built a platform that continuously monitors the MCP threat landscape and visualizes it in 3D.
The Concept: Why "Hive"?
"Hive can be interpreted as a beehive. A beehive can be thought of as a place where intelligence gathers."
We designed MCPThreatHive with biological inspiration:
- Organized Intelligence: Bees exchange messages with no central command, yet the system is highly organized.
- Value Transformation: Agents continuously bring back "pollen" (raw data) from the outside world and transform it into something valuable.
- Living Architecture: A place where MCP threats come in, connect to each other, and evolve into something defenders can actually see.
MCPThreatHive is our contribution to the community->a centralized platform to integrate, classify, and organize the chaos of MCP security.
What This Actually Does
graph LR
A[AI Keyword Gen] --> B[Intel Gathering]
B --> C[AI Analysis]
C --> D[Threat Generation]
D --> E[Threat Matrix]
D --> F[3D Landscape]
E --> G[Mitigation]
F --> G
style A fill:#ff6b6b
style C fill:#feca57
style E fill:#4ecdc4
style F fill:#95e1d3
The Pipeline:
- Gather Intelligence → Continuously collects data from CVEs, security blogs, and whitepapers focused on MCP and LLM security.
- AI Threat Analysis → Uses LiteLLM to analyze gathered intel and extract actionable threat scenarios.
- Generate Threat Models → Maps intelligence to specific MCP risks (MCP-01 to MCP-38).
- 3D Visualization → Projects threats onto an interactive 3D landscape to identify clusters and high-risk zones.
- Real-time Synchronization → The Threat Matrix and 3D Landscape automatically update as new intel arrives.
📌 Terminology
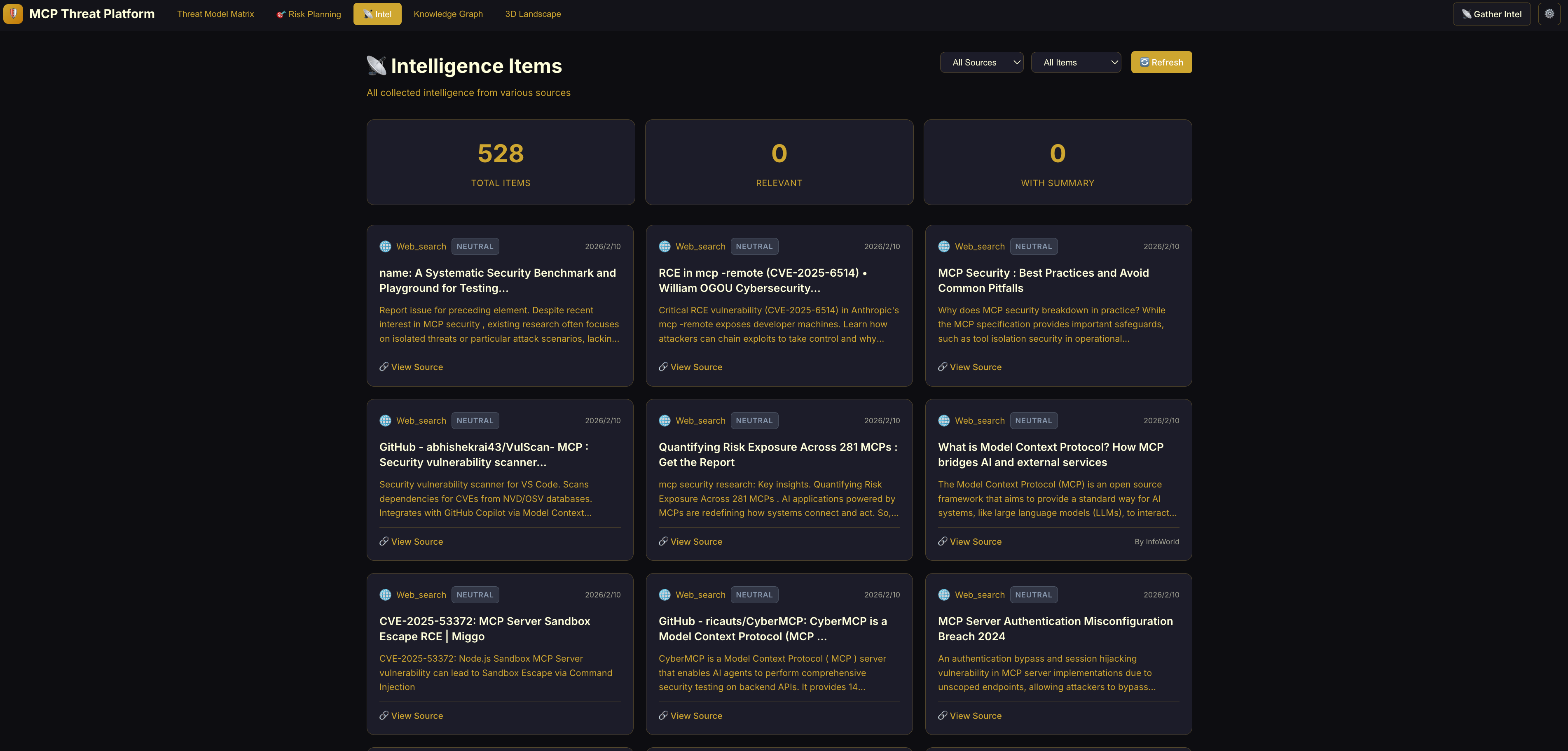
- Intelligence Items: Raw security data collected from external sources (e.g., a CVE entry, a blog post, or a whitepaper). These are the inputs to the system.
- Threats: Specific, structured risk scenarios identified by the AI after analyzing an Intelligence Item. One Intelligence Item can produce multiple Threats (e.g., a single paper might reveal both "Prompt Injection" and "Data Leakage" risks).
Example Scenario: New intel arrives regarding a "Tool Usage Confusion" attack.
- Collector fetches the article.
- Analyzer identifies it as
MCP-10 (Tool Description Poisoning). - Platform creates a new Threat Card.
- 3D Map highlights the "Tool Integration" sector in red.
- Matrix updates the "Spoofing" and "Tool Poisoning" cells.
Real-world Usage
Who is this for?
- Security Researchers: Analyze new MCP tools for potential abuse vectors without manual code review of every update.
- Agentic AI Developers: Visualize the security implications of giving your agent "just one more tool."
- Red Teamers: Identify attack paths in agentic systems (e.g., how a prompt injection leads to RCE via a specific CLI tool).
Common Use Cases:
-
Proactive Risk Management & Secure Development Goal: Enable developers to anticipate risks before implementation, preventing vulnerabilities by design.
Instead of reactively fixing bugs, agent developers use MCPThreatHive during the design phase to understand the security implications of proposed tools. By querying the platform for specific tool categories (e.g., 'File System'), they receive immediate intelligence on known attack vectors like MCP-08 (Path Traversal). This knowledge allows teams to implement necessary controls—such as sandboxing or input validation—during development, creating a "shift-left" security model for agentic systems.
-
Intelligence-Driven Scanner Enhancement Goal: Continuously update organizational defenses with fresh, real-time intelligence.
For security teams maintaining internal vulnerability scanners, MCPThreatHive acts as a continuous intelligence engine. As the platform aggregates and analyzes new MCP threat patterns from the wild (both fresh and historical), this structured intelligence can be integrated into existing scanning pipelines. This ensures that organizational scanners are constantly updated with the latest detection rules, allowing them to identify emerging threats that static rule sets would miss.
-
Incident Investigation Enrichment (SOC) Goal: Accelerate incident response with context-aware vulnerability data.
Security Operations Center (SOC) analysts can consume vulnerability data from MCPThreatHive to enrich incident investigations. When an alert triggers, analysts can query the platform to determine if a host was exploitable via specific MCP attack vectors (e.g., "Was this host vulnerable to MCP-19 Prompt Injection?"), providing critical context for triage and remediation.
Usage Best Practices
⚠️ Performance Warning: Concurrent AI Tasks
To avoid API rate limits, timeouts, or data inconsistencies, do not run multiple AI-intensive tasks simultaneously.
- Avoid running "Gather Intel", "Generate Risk Planning", "Generate from Intel", "Generate from Intel", "Regenerate All", at the same time.
- Wait for one task to complete (or for the notification to appear) before starting another.
- Why? Both features make heavy parallel calls to your LLM provider. Running them together may exceed your provider's concurrency limits (RPM/TPM) and cause the application to fail or hang.
Quick Start
git clone https://github.com/YOURNAME/mcp-threat-platform.git
cd mcp-threat-platform
# Copy and configure
cp .env.example .env
# Edit .env with your LiteLLM key
# Start everything
docker-compose up -d
#You can restart using this command if you encounter any problems
#docker-compose up -d --build --force-recreate
# Wait ~5 minutes for services...
# Then open http://localhost:5000
Installation
If you encounter issues using the Docker installation method above, I recommend following the installation steps below instead, as they are less likely to cause problems. If you still run into any issues, feel free to open an issue and let us know
Local Setup:
-
Start Dependencies (Neo4j): The platform requires Neo4j for the Knowledge Graph and Threat Matrix.
# Start only the Neo4j database (without the web app container) docker-compose up -d neo4j -
Run Application:
python3 -m venv venv && source venv/bin/activate pip install -r requirements.txt # Configuration Manager (Initial Setup & Updates) # Use this to configure or update your LLM models and endpoints at any time. python scripts/interactive_setup.py # Start the API Server # (On the very first run, if not configured, this will also trigger the setup wizard) python -m api.server
Configuration
Interactive Configuration Manager:
The platform includes a configuration tool (scripts/interactive_setup.py) with a main menu that allows you to:
- Run Full Setup Wizard: Recommended for first-time installation.
- Update Model Assignments: Quickly switch models for different AI roles without re-configuring endpoints.
- Manage Endpoints: Add or edit LiteLLM API keys and URLs (supports multi-endpoint configurations).
To launch the configuration manager:
python scripts/interactive_setup.py
Minimal .env:
# LiteLLM API endpoint
LITELLM_API_BASE=https://your-litellm-endpoint.com
# LiteLLM API key (if required by your endpoint)
LITELLM_API_KEY=your-api-key-here
# Default model to use
#If not setup, the AI service won’t work when Docker is started
LITELLM_MODEL=gpt-4o
LITELLM_TEMPERATURE=0.7
# Neo4j connection settings (only needed for Knowledge Graph features)
NEO4J_URI=bolt://localhost:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password #Default password
# Flask environment (development/production)
FLASK_ENV=development
FLASK_DEBUG=1
# Server port (default: 5000)
SERVER_PORT=5000
Configuration: Custom LLM Providers
If you are using a custom LLM provider (e.g., vLLM, private endpoint) via LiteLLM, ThreatHive defaults to using the openai/ prefix for compatibility.
Example Custom Config (.env):
LITELLM_PROVIDER=litellm
LITELLM_API_BASE=https://my-private-llm.corp.local/v1
LITELLM_MODEL=custom-model-name
Modifying Provider Logic:
If your organization requires a different prefix (e.g., azure/, anthropic/, huggingface/), you can modify the provider logic in:
- Keyword Generator:
intel_integration/ai_keyword_generator.py(Search for_call_llm) - Intel Processor:
intel_integration/ai_processor.py(Search for_call_llm)
Identify the provider == "litellm" block and adjust the prefix logic to match your specific model routing requirements.
What you'll see:
-
Intelligence Dashboard: Automated capture of MCP threat intelligence.
-
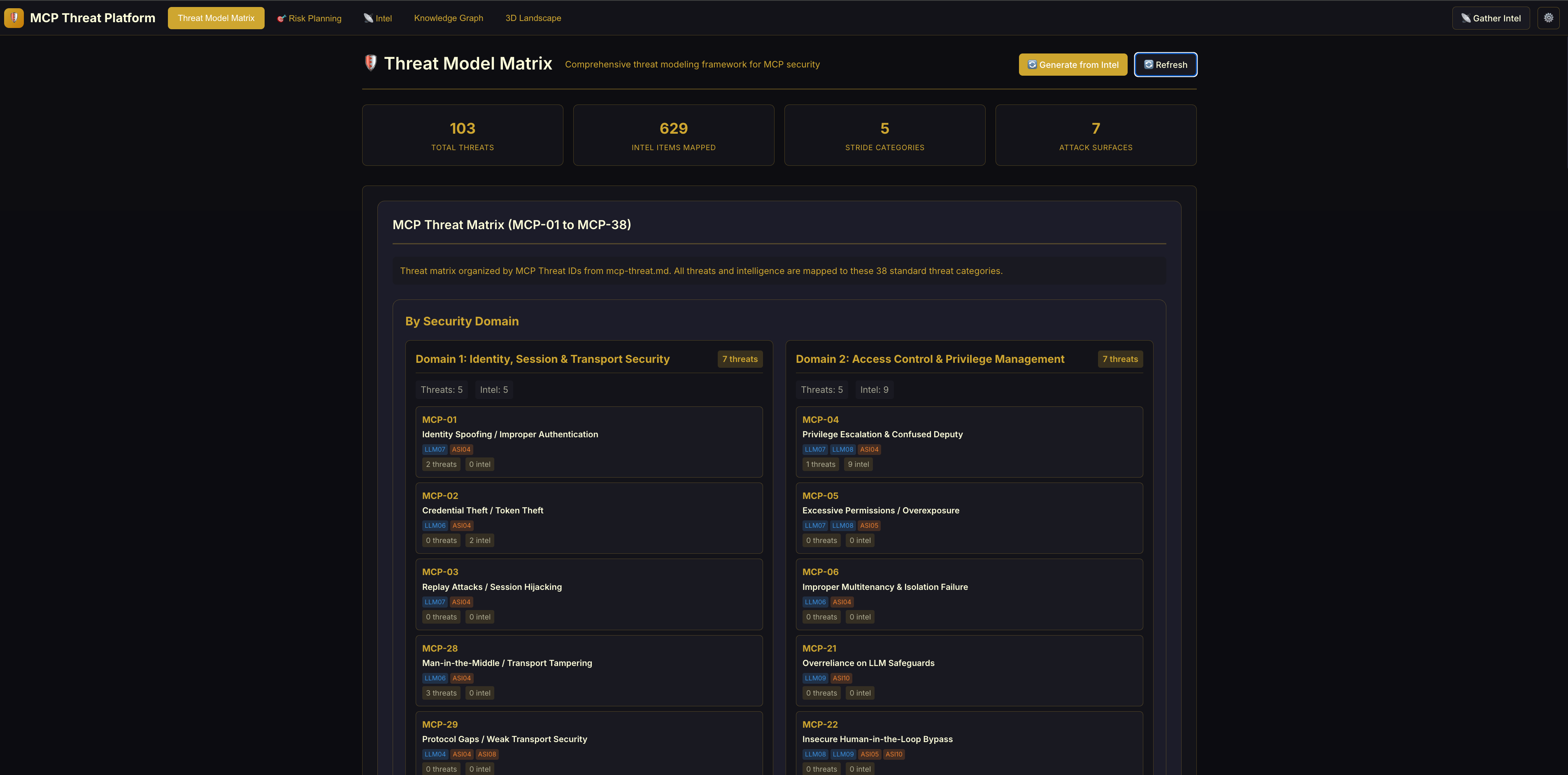
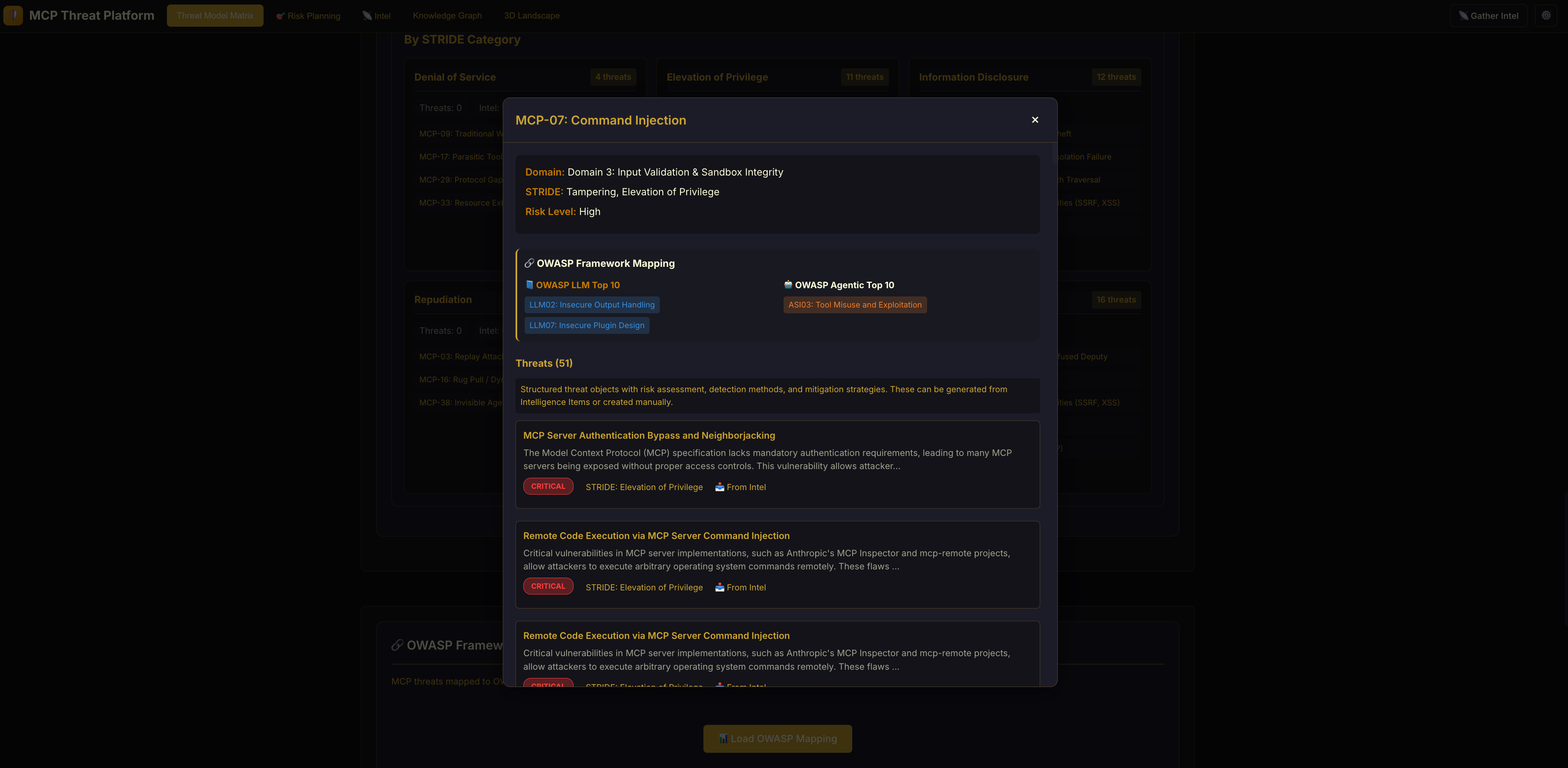
Threat Model Matrix & Analysis: This dashboard visualizes the current threat landscape across three dimensions(Please be sure to press 🔄 Refresh on this page to display all content):
- Threat Matrix: A risk grid based on the MCPSecBench Taxonomy (4 surfaces × 17 attack types) [1]. Red cells indicate high activity or critical risks in that specific area.
- MCP-UPD Attack Chains: Visualizes "Parasitic Tool Chaining" -> how attackers combine benign tools to create complex exploits (e.g., using a harmless "Calculator" tool to obfuscate a command injection).
- STRIDE Analysis: Breakdowns of threats by category (Spoofing, Tampering, etc.), helping specialized security teams focus on their specific domain (e.g., Identity vs. Infrastructure).
| Threat Matrix (Risk Grid) | MCP-UPD Attack Chains (Exploits) | | :------------------------------: | :------------------------------: | |
 |
| 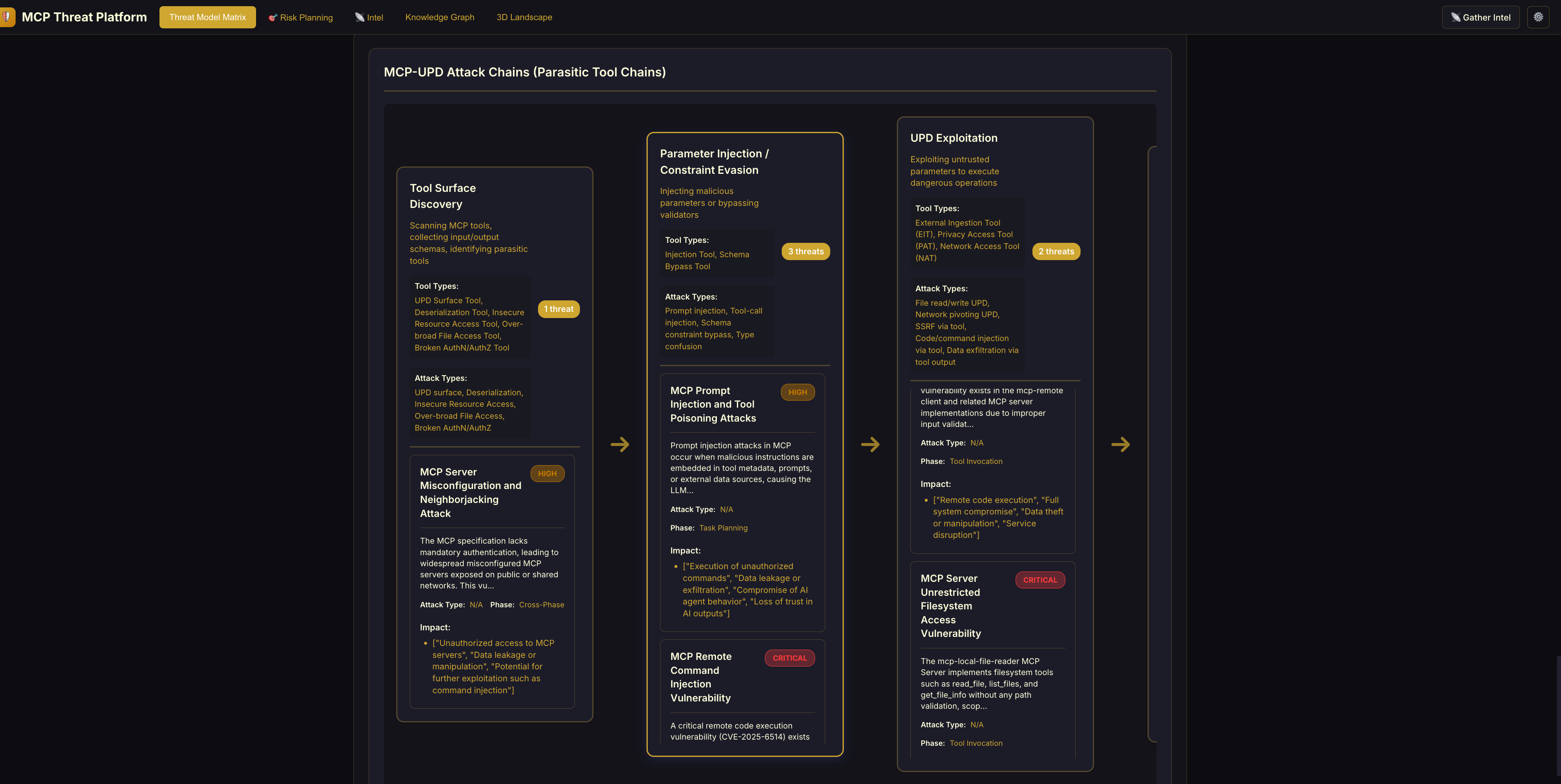 |
| STRIDE: Attack Categories | STRIDE: Risk Distribution |
|
|
| STRIDE: Attack Categories | STRIDE: Risk Distribution |
| 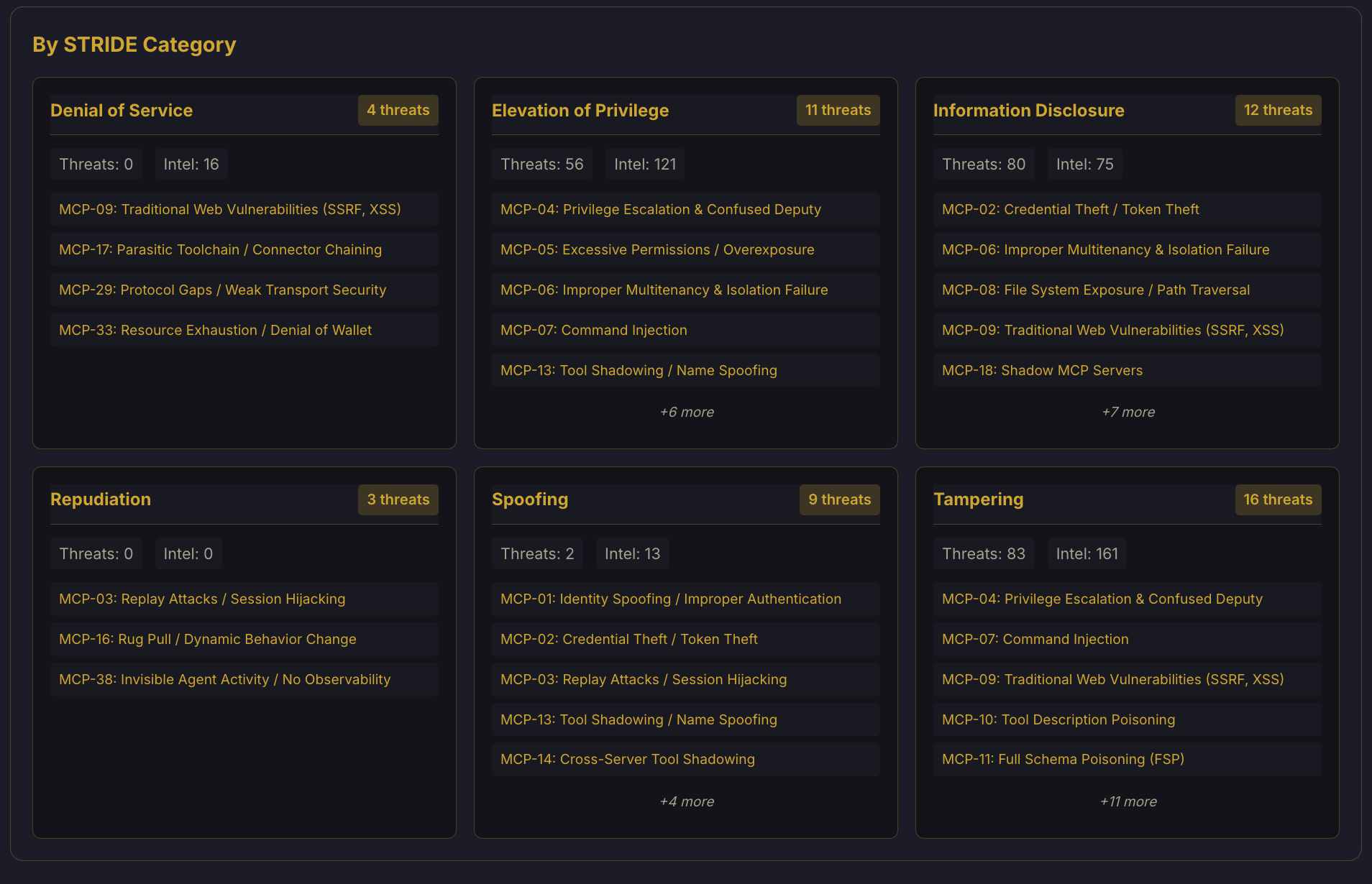 |
|  |
| -
3D Threat Landscape: Interactive 3D visualization of the threat environment.
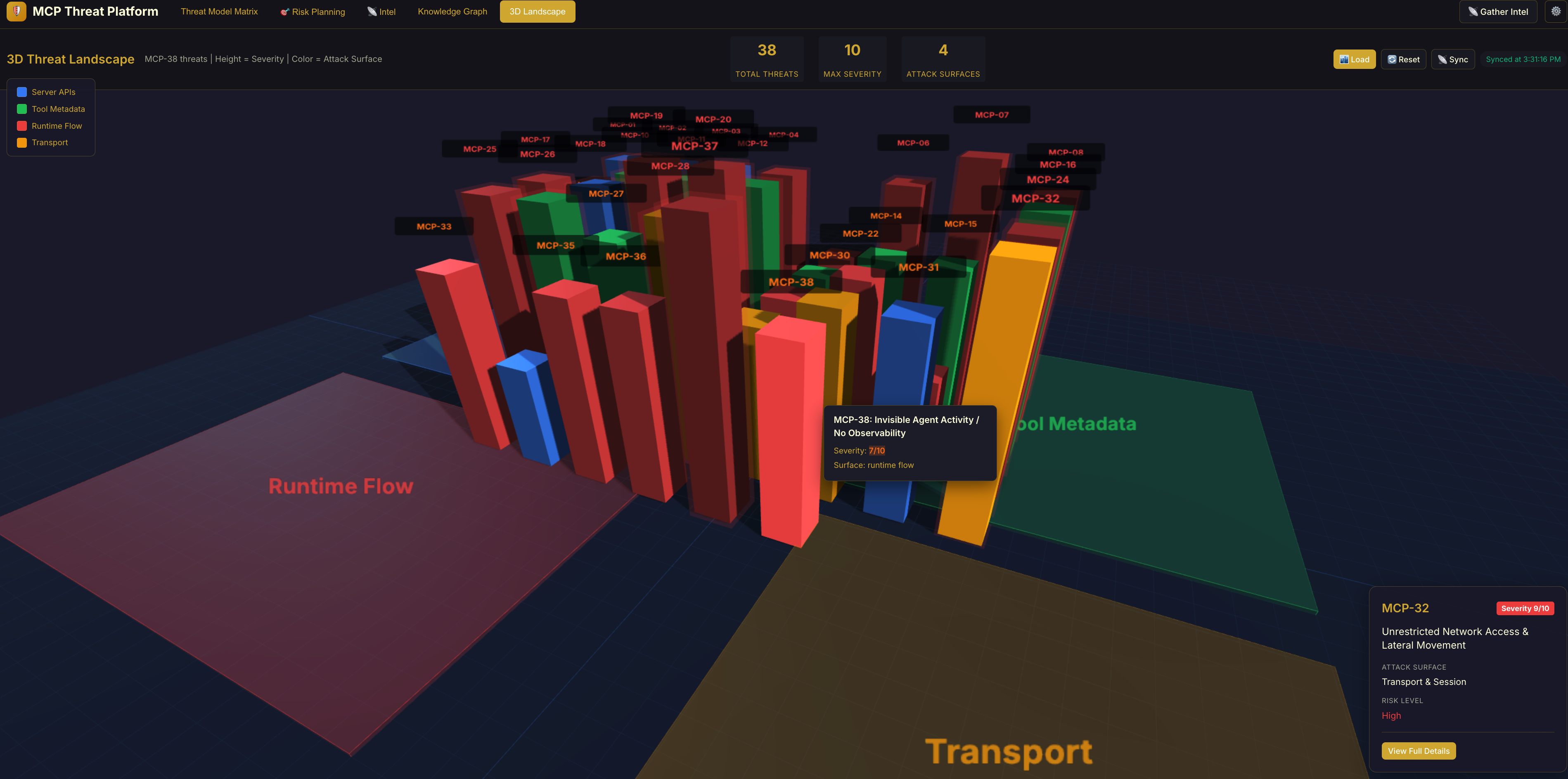
-
Knowledge Graph: Relationships between intelligence sources, threats, and assets.
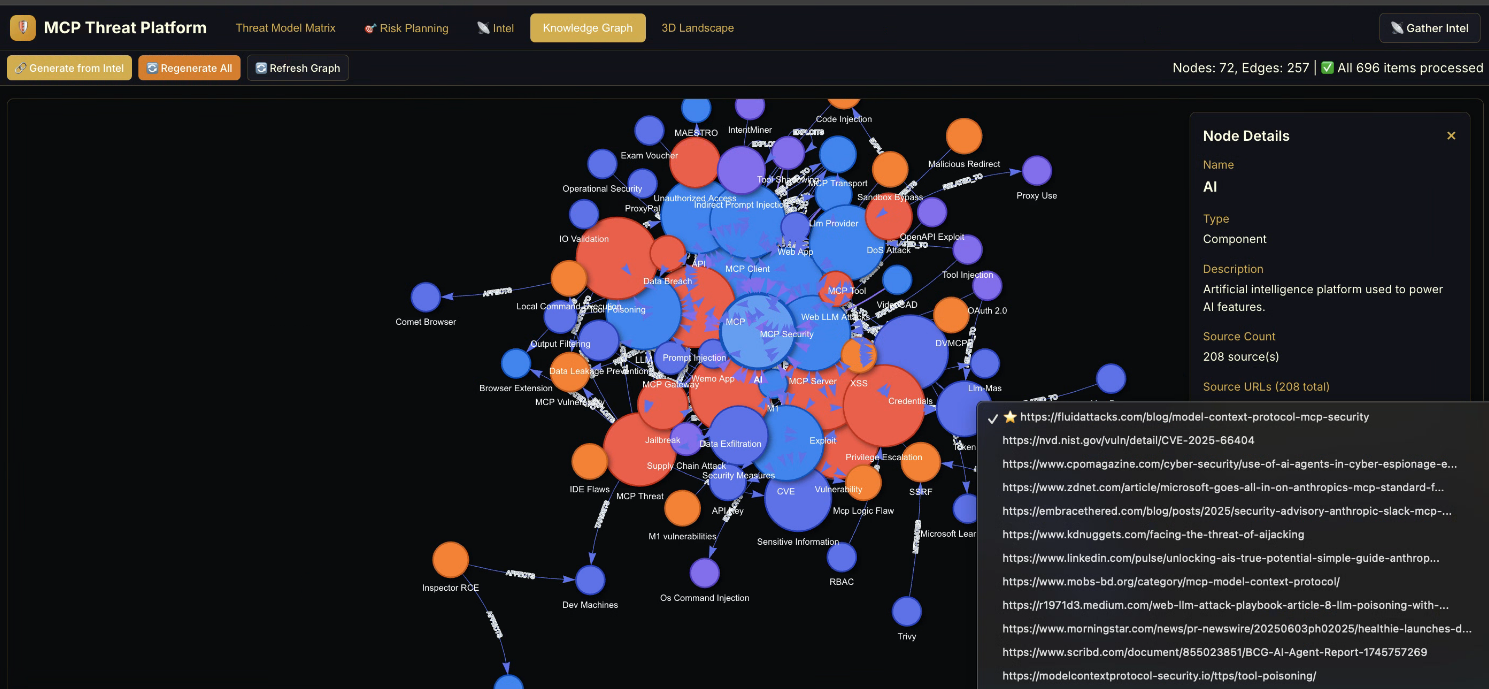
- 🔗 Generate from Intel – If clicking this doesn’t successfully invoke the AI for processing,
- 🔄 Regenerate All – please click here and try again.
-
MCP Risk Planning: AI-powered risk analysis that automatically generates detection methods, mitigation strategies, and security controls for each identified threat. The system analyzes all collected intelligence and threats to produce actionable security recommendations.
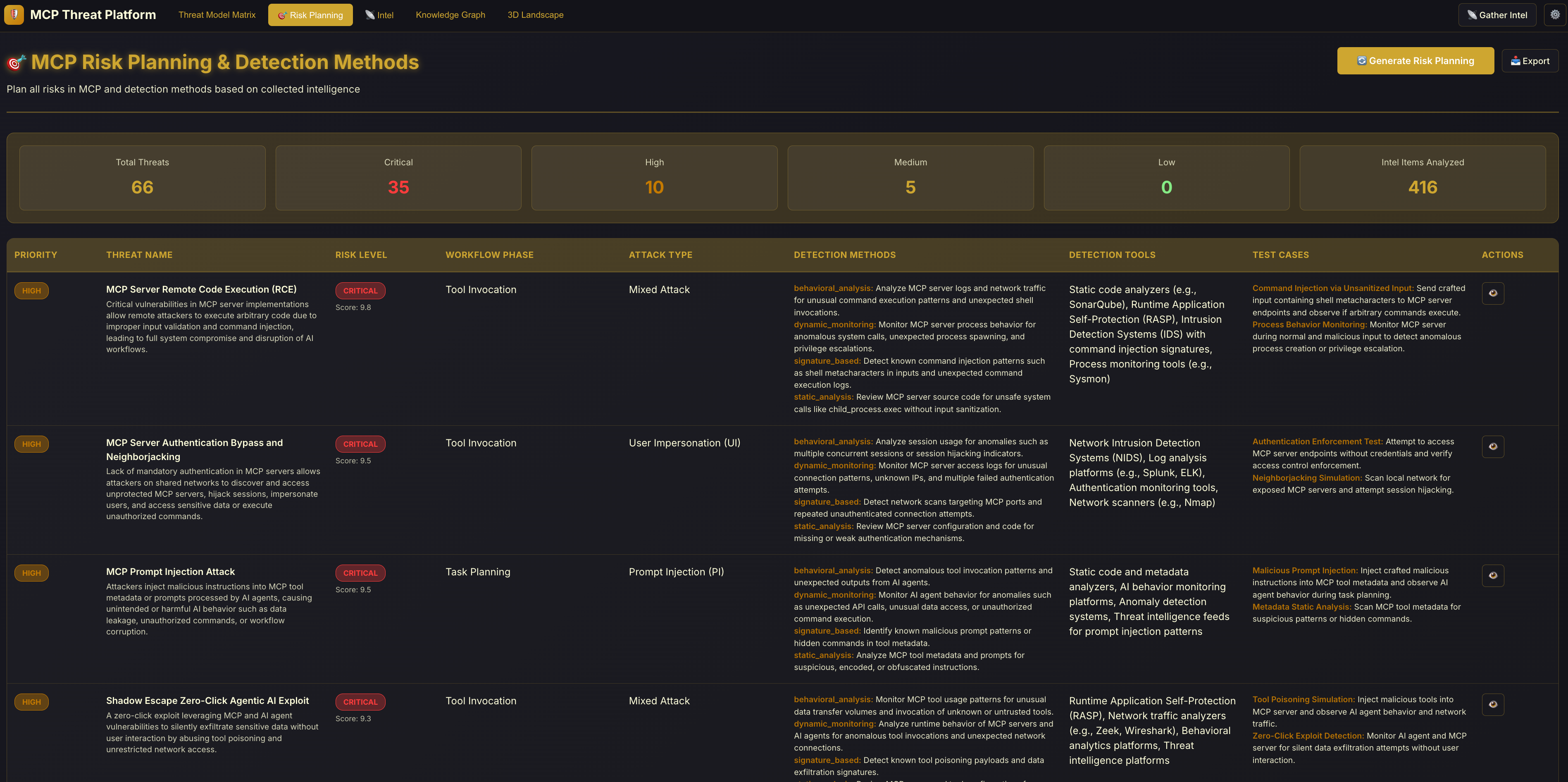
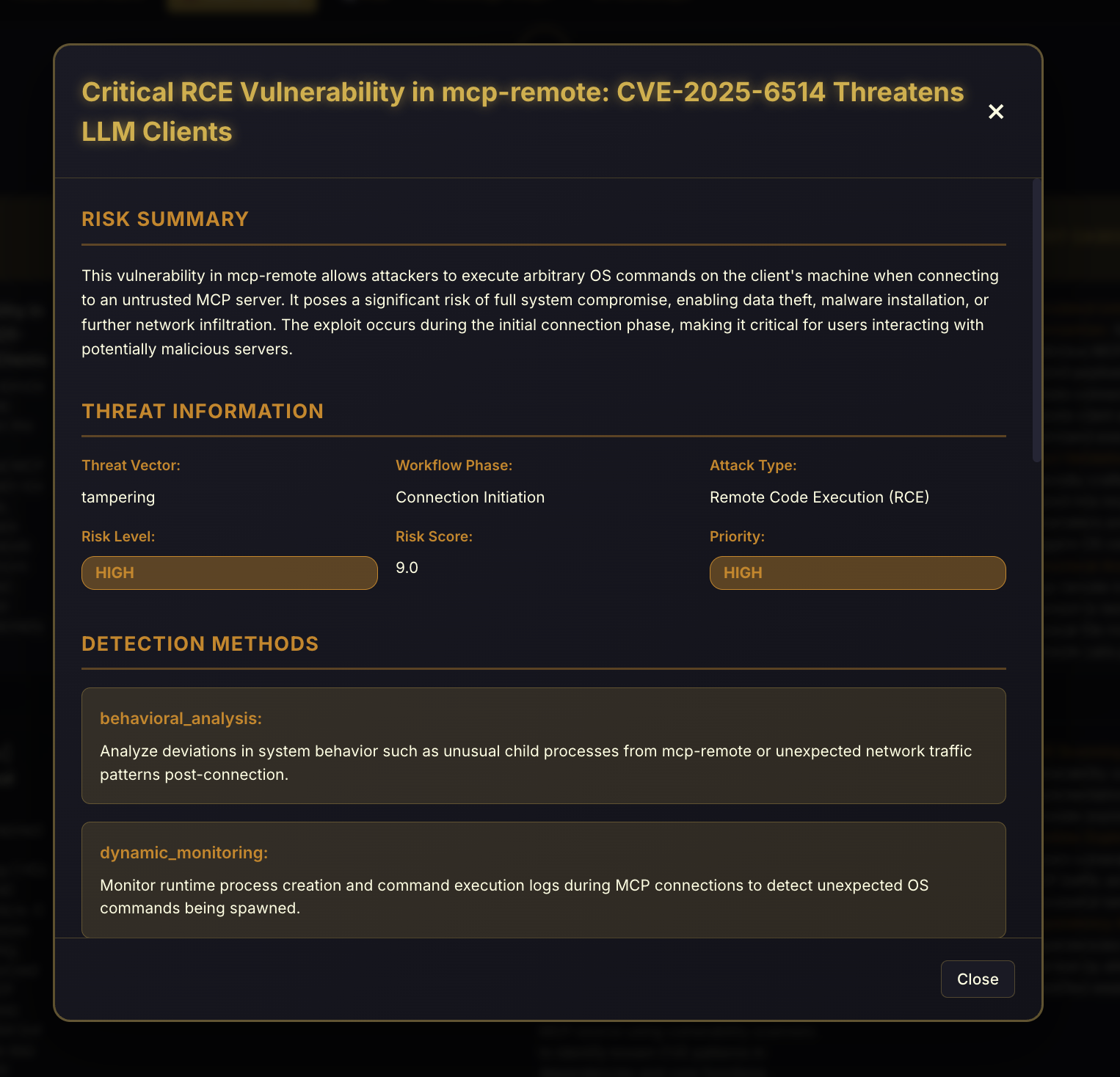
Clicking 'Actions' reveals details:
Architecture
flowchart TB
%% flowchart TB
subgraph Input["1. Intelligence Gathering"]
AIQuery[AI Keyword Generator]
Web[Web Search]
RSS[RSS Feeds]
CVE[CVE Databases]
end
subgraph Process["2. Processing & Analysis"]
Connector[Intel Connector]
Analyzer[LLM Threat Analyzer]
Classifier[OWASP Classifier]
RiskPlanner[AI Risk Planner]
end
subgraph Store["3. Storage"]
DB[(Neo4j / SQLite)]
KG[Knowledge Graph]
end
subgraph View["4. Visualization & Planning"]
Matrix[Threat Matrix]
ThreeD[3D Landscape]
Canvas[Architecture Canvas]
RiskPlan[Risk Planning Dashboard]
end
AIQuery --> Web
Web --> Connector
RSS --> Connector
CVE --> Connector
Connector --> Analyzer
Analyzer --> Classifier
Classifier --> DB
DB --> KG
DB --> Matrix
DB --> ThreeD
DB --> Canvas
DB --> RiskPlanner
RiskPlanner --> RiskPlan
style AIQuery fill:#ff9f43
style Analyzer fill:#ff6b6b
style RiskPlanner fill:#ee5a6f
style ThreeD fill:#4ecdc4
style Matrix fill:#95e1d3
style KG fill:#a29bfe
Key Components:
| Component | Purpose |
| ----------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| Intel Collector | Aggregates security data from external sources
When the platform starts, please use 📡 Gather Intel to collect intelligence first;
otherwise, no information will be displayed on the platform |
| LLM Threat Analyzer | Uses AI to convert raw intel into structured Threat Cards |
| OWASP Classifier | Maps threats to Web, LLM, and Agentic App security frameworks |
| AI Risk Planner | Analyzes all threats and generates detection methods, mitigation strategies, and security controls |
| 3D Landscape | Visualizes threat clusters and intensity in a 3D space |
| Threat Matrix | Grid view of threats organized by Attack Surface and STRIDE |
| Knowledge Graph | Graph database linking Intel -> Threats -> Assets -> Controls |
| Risk Planning | Dashboard displaying AI-generated risk analysis, detection methods, and mitigation recommendations |
Threat Frameworks
MCPThreatHive uses a multi-framework approach to ensure comprehensive threat coverage. Every threat is analyzed through multiple security lenses simultaneously, providing defense teams with actionable insights across different security domains.
Framework Integration Overview
graph LR
Intel[Intelligence Item] --> Analyzer[AI Threat Analyzer]
Analyzer --> ThreatMatrix["Standard Threat Matrix\n4×17"]
Analyzer --> MCP38["MCP-38 Threat Catalog"]
Analyzer --> OWASP["OWASP Triple Classification"]
ThreatMatrix --> ThreatCard[Unified Threat Card]
MCP38 --> ThreatCard
OWASP --> ThreatCard
ThreatCard --> Matrix[Threat Matrix]
ThreatCard --> ThreeD[3D Landscape]
ThreatCard --> RiskPlan[Risk Planning]
style Analyzer fill:#ff6b6b
style ThreatCard fill:#feca57
style Matrix fill:#4ecdc4
Why Multiple Frameworks?
- Threat Matrix: Provides systematic attack surface coverage (where the attack happens)
- MCP 1-38 Catalog: Offers specific MCP threat patterns (what the attack does)
- OWASP Triple: Maps to industry-standard security frameworks (how to communicate with different teams)
1. MCPSecBench-based Threat Matrix
The Threat Matrix is a systematic security framework specifically designed for Model Context Protocol ecosystems. It provides 4 attack surfaces × 17 attack types = 68 threat scenarios.
Attack Surfaces & Frontend Mapping
The 3D Threat Landscape in the frontend visualizes these risks across 4 distinct zones. Here is how they map to the MCPSecBench taxonomy:
| Frontend Zone (3D View) | MCPSecBench Surface | Focus Area | | ----------------------- | -------------------- | ------------------------------------------------------------------------------ | | Runtime Flow | User Interaction | Attacks driven by malicious input or prompt context (e.g., Prompt Injection). | | Tool Metadata | Client Surface | Flaws in MCP client implementation, configuration, or schema handling. | | Transport | Protocol Surface | Attacks at the network/transport layer (e.g., MitM, Rebinding). | | Server APIs | Server Surface | Threats aimed at tool logic, server configuration, and execution environments. |
📌 MCPSecBench – Taxonomy of 17 Attack Types
The platform implements the 17 attack types defined by the MCPSecBench paper (arXiv:2508.13220), categorized by their surface:
1) User Interaction Surface (Runtime Flow)
- Prompt Injection – Malicious inputs that subvert intended agent workflows.
- Tool/Service Misuse (“Confused AI”) – Malware triggers due to deceptive natural language tool descriptions.
2) Client Surface (Tool Metadata)
- Schema Inconsistencies – Outdated or broken client schemas preventing secure operations.
- Slash Command Overlap – Conflicting command names lead to unintended tool invocation.
- Vulnerable Client Exploitation – Exploiting implementation flaws (e.g., CVE-2025-6514) to achieve RCE.
3) Protocol Surface (Transport)
- MCP Rebinding – DNS or connection manipulation redirects client connections to malicious endpoints.
- Man-in-the-Middle (MitM) – Interception/modification of protocol messages due to insecure transport.
4) Server Surface (Server APIs)
- Tool Shadowing – Injecting deceptive tool descriptions so the agent invokes unintended tools.
- Data Exfiltration via Metadata – Tricking the protocol into leaking sensitive data (conversations, tool lists).
- Package Name Squatting (Tool Level) – Tools with misleading names confuse selection logic.
- Indirect Prompt Injection – Malicious content embedded in resources altering behavior.
- Package Name Squatting (Server Level) – Spoofed server identities mislead routing decisions.
- Configuration Drift – Insecure server configurations expose internal systems.
- Sandbox Escape – Breaking out from restricted execution environments.
- Tool Poisoning – Malicious tools prioritized via deceptive manifests.
- Vulnerable Server Exploitation – Exploiting server bugs (path traversal, SQLi).
- Rug Pull Attack – Servers behaving benignly at first, then switching to malicious behavior.
(This taxonomy is established by MCPSecBench for comprehensive MCP security evaluation)
Application in Platform
These 17 attack types are rigorously applied across the platform's architecture:
- AI Threat Classification: The
IntelPipelineandRiskPlanneruse theMCPSecBenchAttackTypeenum to classify every incoming threat intelligence item. - Standardized Data Schema: The database schema (
schemas/mcpsecbench_schema.py) enforces these 17 types as the source of truth for all threat records, ensuring consistency between the UI and the underlying data.
2. MCP 1-38 Threat Catalog
The MCP 1-38 Threat Catalog is our curated collection of 38 specific MCP threat patterns (MCP-01 to MCP-38), organized by security domain. Each threat has a unique ID, detailed description, and mapped mitigations.
| Domain | Threat IDs | Focus Area | Example Threats | | ----------------------------- | ---------------- | -------------------------------------- | ------------------------------------------------------------------------------ | | Identity & Authentication | MCP-01 to MCP-05 | User/agent identity verification | Identity spoofing, credential theft, session hijacking, token replay | | Access Control | MCP-06 to MCP-10 | Authorization and privilege management | Privilege escalation, tool shadowing, RBAC bypass, unauthorized tool access | | Input Validation | MCP-11 to MCP-15 | User input and parameter handling | Prompt injection, command injection, SQL injection, XSS via tool output | | Data Integrity | MCP-16 to MCP-22 | Data protection and confidentiality | Data exfiltration, memory poisoning, context manipulation, PII leakage | | Supply Chain | MCP-23 to MCP-28 | Dependencies and external code | Registry tampering, malicious packages, dependency confusion, backdoored tools | | Resource Abuse | MCP-29 to MCP-34 | System resources and availability | DoS attacks, context flooding, compute hijacking, rate limit bypass | | Observability | MCP-35 to MCP-38 | Logging, monitoring, and audit trails | Audit evasion, log tampering, monitoring blind spots, forensic anti-analysis |
Complete MCP-38 Threat
| ID | Threat Name | Risk Level | Key Risk Rationale | | ---------- | ---------------------------------------------- | ---------- | ---------------------------------------------------------------------------------- | | MCP-01 | Identity Spoofing / Improper Authentication | High | Identity forgery leads to unauthorized access and audit trail failures | | MCP-02 | Credential Theft / Token Theft | High | Stolen credentials enable complete impersonation of legitimate agents | | MCP-03 | Replay Attacks / Session Hijacking | High | Replay enables repeated execution of sensitive operations (e.g., transfers, leaks) | | MCP-04 | Privilege Escalation & Confused Deputy | High | Privilege escalation grants direct access to higher-level permissions | | MCP-05 | Excessive Permissions / Overexposure | Medium | Over-permissioning has high impact but requires agent control first | | MCP-06 | Improper Multitenancy & Isolation Failure | High | Cross-tenant leakage or escalation affects entire multi-tenant systems | | MCP-07 | Command Injection | Critical | Direct RCE with full server compromise | | MCP-08 | File System Exposure / Path Traversal | High | Arbitrary file read/write leads to data leakage or backdoor installation | | MCP-09 | Traditional Web Vulnerabilities (SSRF, XSS) | Medium | SSRF/XSS enables internal network probing or session hijacking via HTTP exposure | | MCP-10 | Tool Description Poisoning | High | Misleads LLM into executing arbitrary tool calls | | MCP-11 | Full Schema Poisoning (FSP) | High | Schema poisoning affects all invocations and is difficult to detect | | MCP-12 | Resource Content Poisoning | High | Persistent indirect injection affects long-term behavior | | MCP-13 | Tool Shadowing / Name Spoofing | Medium | Misleads LLM to select wrong tools; limited impact but aids other attacks | | MCP-14 | Cross-Server Tool Shadowing | Medium | Cross-server tool call hijacking has higher impact but requires specific setup | | MCP-15 | Preference Manipulation Attack (PMPA) | Medium | Biases LLM tool selection; affects decisions but rarely causes direct harm | | MCP-16 | Rug Pull / Dynamic Behavior Change | High | Post-trust malicious transformation has severe impact | | MCP-17 | Parasitic Toolchain / Connector Chaining | High | Tool chain abuse bypasses controls or exfiltrates data | | MCP-18 | Shadow MCP Servers | High | Hidden servers enable long-term unmonitored malicious operations | | MCP-19 | Prompt Injection (Direct) | Critical | Direct system prompt override leads to arbitrary behavior | | MCP-20 | Prompt Injection (Indirect via Data) | Critical | Indirect injection is hard to prevent and has persistent impact | | MCP-21 | Overreliance on LLM Safeguards | Medium | Over-dependence on LLM protections is easily bypassed | | MCP-22 | Insecure Human-in-the-Loop Bypass | Medium | Bypasses human approval but requires user interaction | | MCP-23 | Consent / Approval Fatigue | Low | User fatigue leads to mistaken approvals; indirect impact | | MCP-24 | Data Exfiltration via Tool Output | High | Tool output directly leaks sensitive data | | MCP-25 | Privacy Inversion / Data Aggregation Leakage | High | Aggregation leakage enables privacy inversion attacks | | MCP-26 | Supply Chain Compromise | High | Supply chain compromise plants backdoors affecting entire ecosystem | | MCP-27 | Missing Integrity Verification | High | Lack of integrity checks enables tampering | | MCP-28 | Man-in-the-Middle / Transport Tampering | High | MITM intercepts/tampers all traffic | | MCP-29 | Protocol Gaps / Weak Transport Security | Medium | Weak protocols are exploitable but require transport layer exposure | | MCP-30 | Insecure stdio Descriptor Handling | Medium | Improper stdio handling leads to process hijacking | | MCP-31 | MCP Endpoint / DNS Rebinding | Medium | DNS rebinding tricks local clients into connecting to malicious endpoints | | MCP-32 | Unrestricted Network Access & Lateral Movement | High | Lateral movement enables attacks on other internal systems | | MCP-33 | Resource Exhaustion / Denial of Wallet | Medium | Resource exhaustion causes DoS or financial loss | | MCP-34 | Tool Manifest Reconnaissance | Low | Reconnaissance of tool manifests has limited impact | | MCP-35 | Planning / Agent Logic Drift | Medium | Logic drift affects long-term behavior but requires multi-round manipulation | | MCP-36 | Multi-Agent Context Hijacking | Medium | Context hijacking affects multi-agent collaboration | | MCP-37 | Sandbox Escape | Critical | Sandbox escape grants direct host system access | | MCP-38 | Invisible Agent Activity / No Observability | Medium | Lack of observability makes malicious activity hard to track |
How to Use MCP IDs:
- Threat Cards: Each generated threat is tagged with relevant MCP IDs (e.g.,
MCP-11,MCP-19) - Risk Planning: Detection methods reference specific MCP IDs for targeted monitoring
- Knowledge Graph: Threats are linked by shared MCP categories for pattern discovery
- 3D Landscape: Threats cluster by MCP domain, revealing concentration areas
3. OWASP Dual Classification
Every threat in MCPThreatHive is simultaneously classified across two OWASP frameworks, enabling cross-domain security analysis and communication with different security teams.
| Framework | Coverage | Purpose | | ------------------------------------------------------ | ----------- | ---------------------------------------------------------------- | | OWASP Top 10 for Large Language Model Applications | LLM01-LLM10 | Identifies LLM-specific attack vectors for AI security teams | | OWASP Top 10 for Agentic Applications | ASI01-ASI10 | Covers agentic system risks for autonomous agentic AI developers |
Sample Multi-Framework Mappings
| MCP Threat | Description | OWASP LLM | OWASP Agentic |
| ---------- | --------------------------------- | --------------------------------------------------- | --------------------------------------------------- |
| MCP-01 | Identity Spoofing | LLM02 (Insecure Output)
LLM06 (Sensitive Info) | ASI03 (Identity Confusion)
ASI07 (Auth Bypass) |
| MCP-07 | Command Injection | LLM05 (Insecure Plugin Design) | ASI05 (Tool Execution Risk) |
| MCP-10 | Tool Description Poisoning | LLM03 (Training Data Poisoning) | ASI04 (Tool Poisoning) |
| MCP-19 | Direct Prompt Injection | LLM01 (Prompt Injection) | ASI01 (Agent Goal Hijacking) |
| MCP-24 | Data Exfiltration via Tool Output | LLM02 (Insecure Output Handling) | ASI02 (Data Leakage) |
| MCP-26 | Supply Chain Compromise | LLM03 (Supply Chain) | ASI04 (Malicious Tool Injection) |
| MCP-37 | Sandbox Escape | LLM05 (Insecure Plugin Design) | ASI05 (Execution Boundary Violation) |
⚠️ Limitations & Disclaimer
AI Classification Accuracy: This platform uses Large Language Models to analyze and classify threat intelligence. While we optimize prompts for accuracy, AI models can hallucinate or misclassify technical details.
- False Positives: Innocent tool descriptions might be flagged as malicious.
- Misclassification: A "Prompt Injection" might be mislabeled as "Jailbreak".
- Human Review Required: Always verify critical findings manually before taking blocking actions.
We are continuously improving our classification pipeline. Please treat the "Threat Level" and "Category" as strong indicators, not absolute truths.
License
Apache License 2.0 - see LICENSE
References & Acknowledgements
- Model Context Protocol: Official documentation at modelcontextprotocol.io.
- MCPSecBench: The threat matrix structure (4 surfaces × 17 attack types) and taxonomy are directly adapted from this framework to ensure consistent AI tagging and misalignment detection.
- Paper: https://arxiv.org/abs/2508.13220 (Used for: Threat Matrix Taxonomy, Attack Type Classification)
- OWASP: Threat classifications align with OWASP Top 10 for LLM Applications (LLM01-LLM10) and OWASP Top 10 for Agentic AI (ASI01-ASI10) to provide industry-standard risk mapping.
- MCP Security Bench (MSB): Benchmarking Attacks Against Model Context Protocol in LLM Agents
- Paper: https://arxiv.org/abs/2510.15994 (Used for: Vulnerability Scoring, Benchmarking Baselines)
- MPMA: Preference Manipulation Attack Against Model Context Protocol
- Paper: https://arxiv.org/abs/2505.11154 (Used for: Identifying MCP-15 Preference Manipulation scenarios in the AI Threat Analyzer)
- Mind Your Server: A Systematic Study of Parasitic Toolchain Attacks on the MCP Ecosystem
- Paper: https://arxiv.org/pdf/2509.06572 (Used for: Detecting "Parasitic Tool Chain" (MCP-17) and "Tool-to-Tool" parasitic behaviors in the Knowledge Graph)
Technical Documentation
For a detailed explanation of the algorithms, AI techniques, and risk assessment methodologies used in this platform, please refer to the Technical Architecture Report.